
© 2021 htr3n
CC BY-SA 4.0
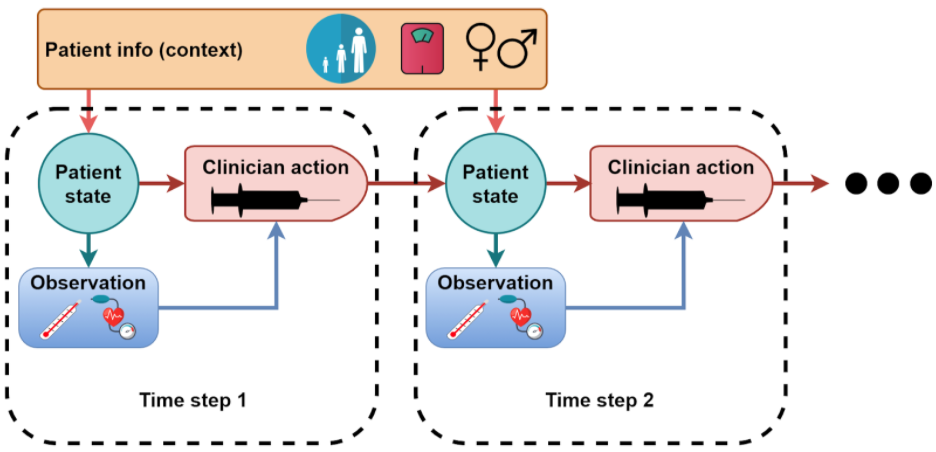
Real-world sequential decision problems often share two important properties – the reward function is often unknown, yet expert demonstrations can be acquired, and there often exists a static parameter, also known as the context, which determines certain aspects of the problem. In this work we formalize the Contextual Inverse Reinforcement Learning framework, propose several algorithms and analyze them both theoretically and empirically.
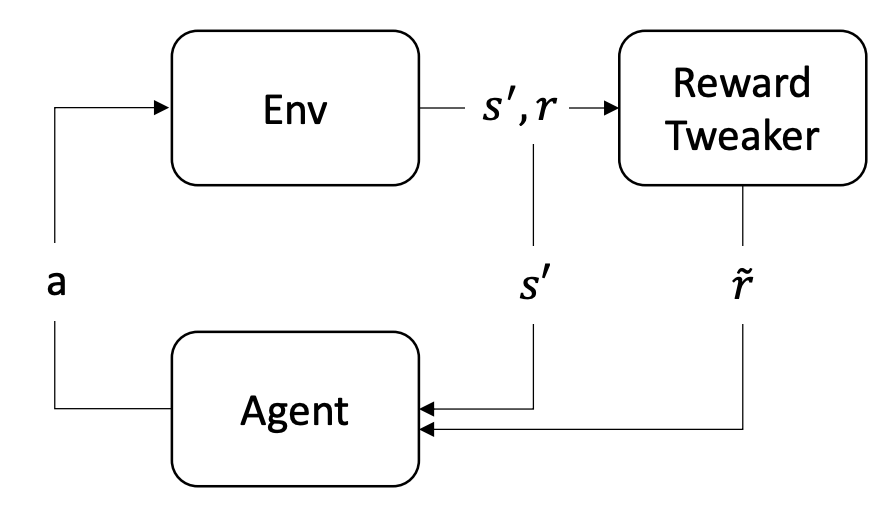
In many practical applications, we train the agent on the $\gamma$-discounted task and evaluate it on the total reward. The discrepancy between training and evaluation may lead to sub-optimal solutions. Reward tweaking learns an alternative surrogate reward, aimed to guide the agent towards better behavior on the evaluation metric.
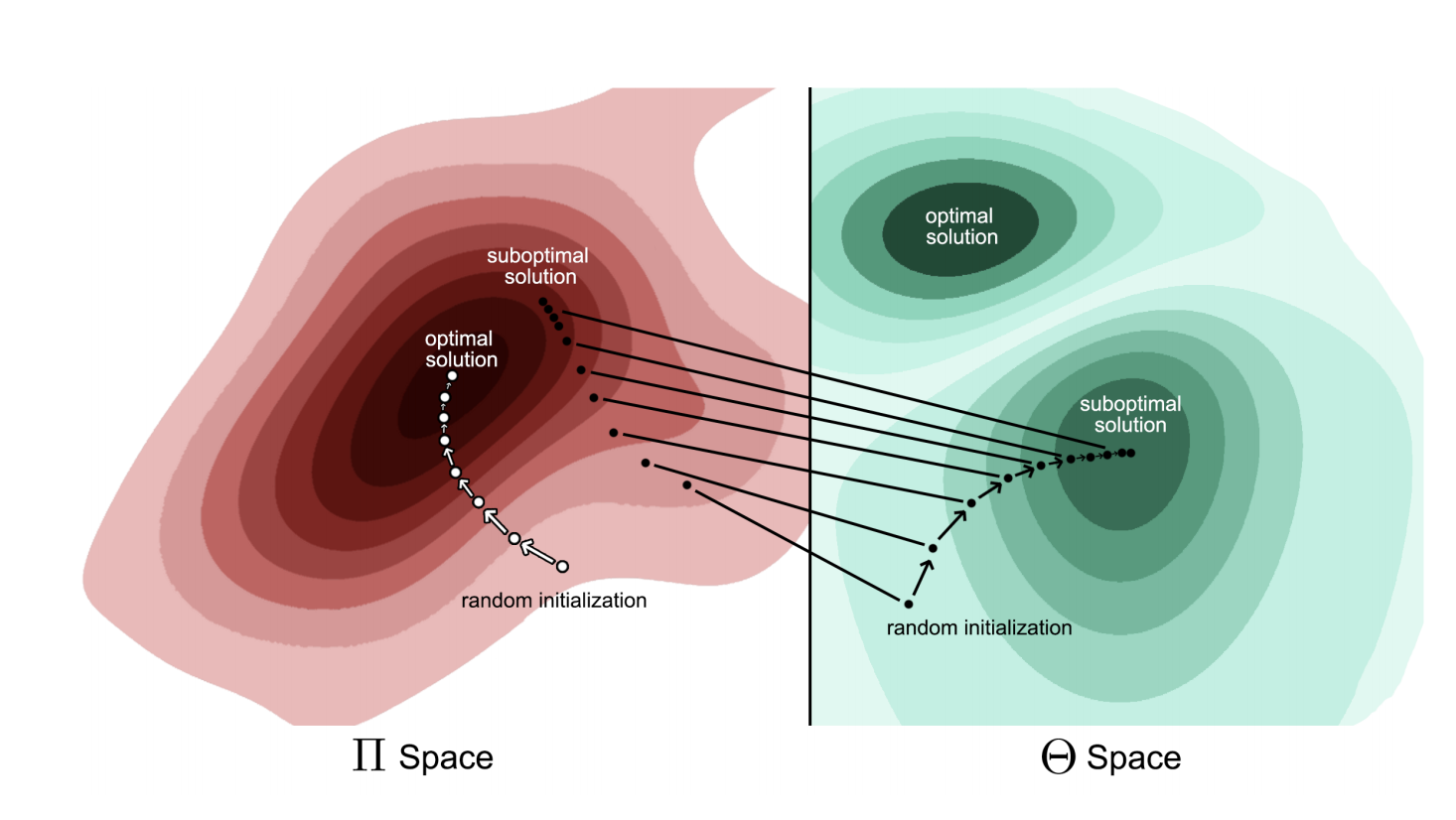
We propose a method for learning distributional policies, policies which are not limited to parametric distribution functions (e.g., Gaussian and Delta). This approach overcomes sub-optimal local extremum in continuous control regimes.

Action Robust is a special case of robustness, in which the agent is robust to uncertainty in the performed action. We show (theoretically) that this form of robustness has efficient solutions and (empirically) results in policies which are robust to common uncertainties in robotic domains.
Learning a policy which adheres to behavioral constraints is an important task. Our algorithm, RCPO, enables the satisfaction of not only discounted constraints but also average and probabilistic, in an efficient manner.
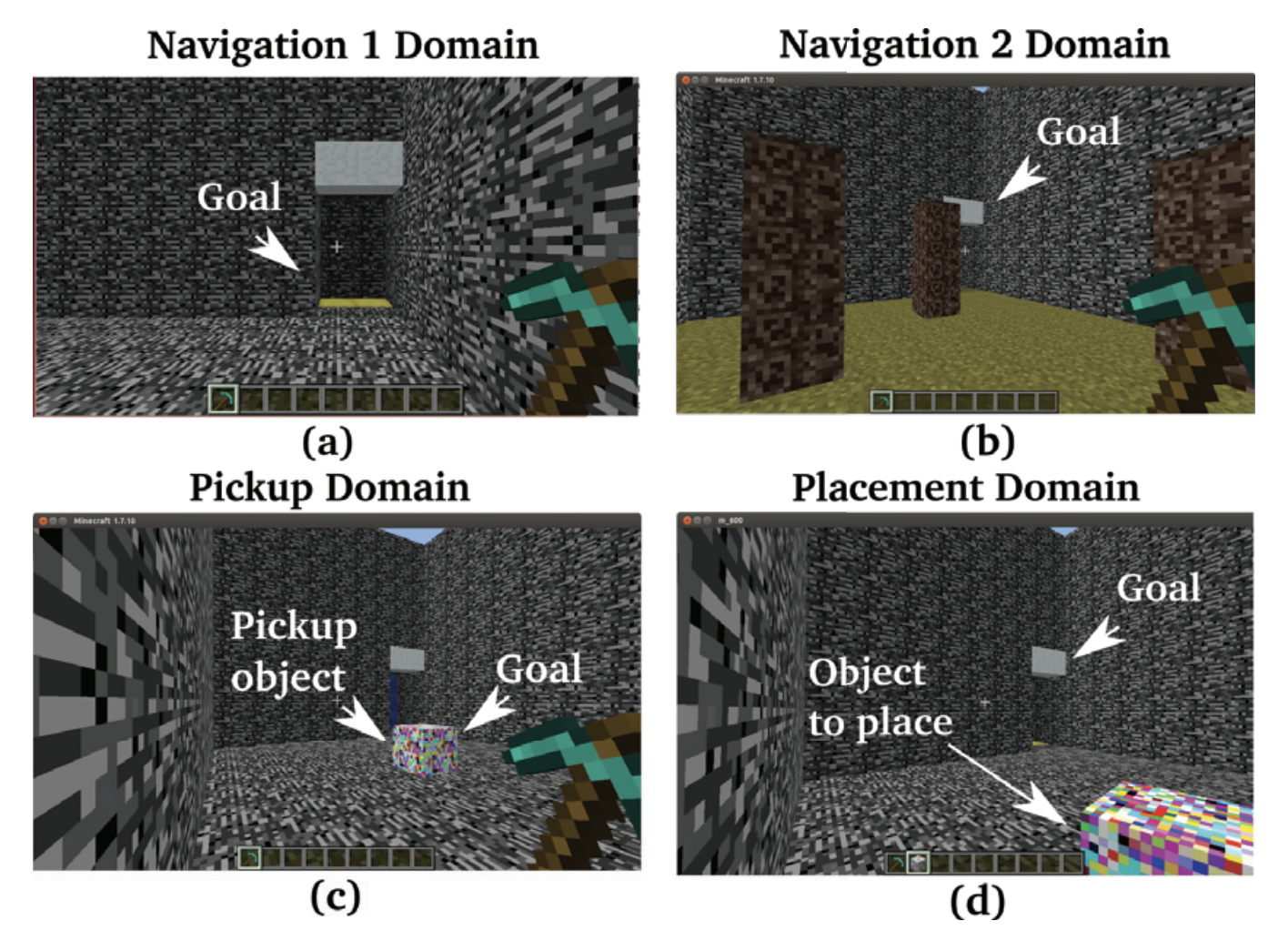
We propose a lifelong learning system that has the ability to reuse and transfer knowledge from one task to another while efficiently retaining the previously learned knowledge-base. Knowledge is transferred by learning reusable skills to solve tasks in Minecraft, a popular video game which is an unsolved and high-dimensional lifelong learning problem.